World Models in a Closed-Loop World
The first comprehensive closed-loop benchmark for visual world models.
1 JHU, 2 PKU, 3 Princeton, 4 MIT, 5 Harvard
By grounding assessment in embodied task success instead of video metrics, ![]() provides a principled yardstick for future research on generative world models in the context of embodiment.
provides a principled yardstick for future research on generative world models in the context of embodiment.
Abstract
Generative world models (WMs) can now simulate worlds with striking visual realism, which naturally raises the question of whether they can endow embodied agents with predictive perception for decision making. Progress on this question has been limited by fragmented evaluation: most existing benchmarks adopt open-loop protocols that emphasize visual quality in isolation, leaving the core issue of embodied utility unresolved, i.e., do WMs actually help agents succeed at embodied tasks?
To address this gap, we introduce ![]() , the first open platform that benchmarks WMs in a closed-loop world that mirrors real agent-environment interactions.
, the first open platform that benchmarks WMs in a closed-loop world that mirrors real agent-environment interactions. ![]() provides a unified online planning strategy and a standardized action API, enabling heterogeneous WMs for decision making.
provides a unified online planning strategy and a standardized action API, enabling heterogeneous WMs for decision making.
We curate four closed-loop environments that rigorously evaluate diverse WMs, prioritize task success as the primary metric, and move beyond the common focus on visual quality; we also present the first data scaling law for world models in embodied settings.
Our study uncovers three surprises: (1) visual quality alone does not guarantee task success—controllability matters more; (2) scaling post-training with action-observation data is more effective than upgrading the pretrained video generators; and (3) allocating more inference-time compute allows WMs to substantially improve closed-loop performance. By centering evaluation on closed-loop outcomes, ![]() establishes a new benchmark for the systematic assessment of WMs.
establishes a new benchmark for the systematic assessment of WMs.
Overview
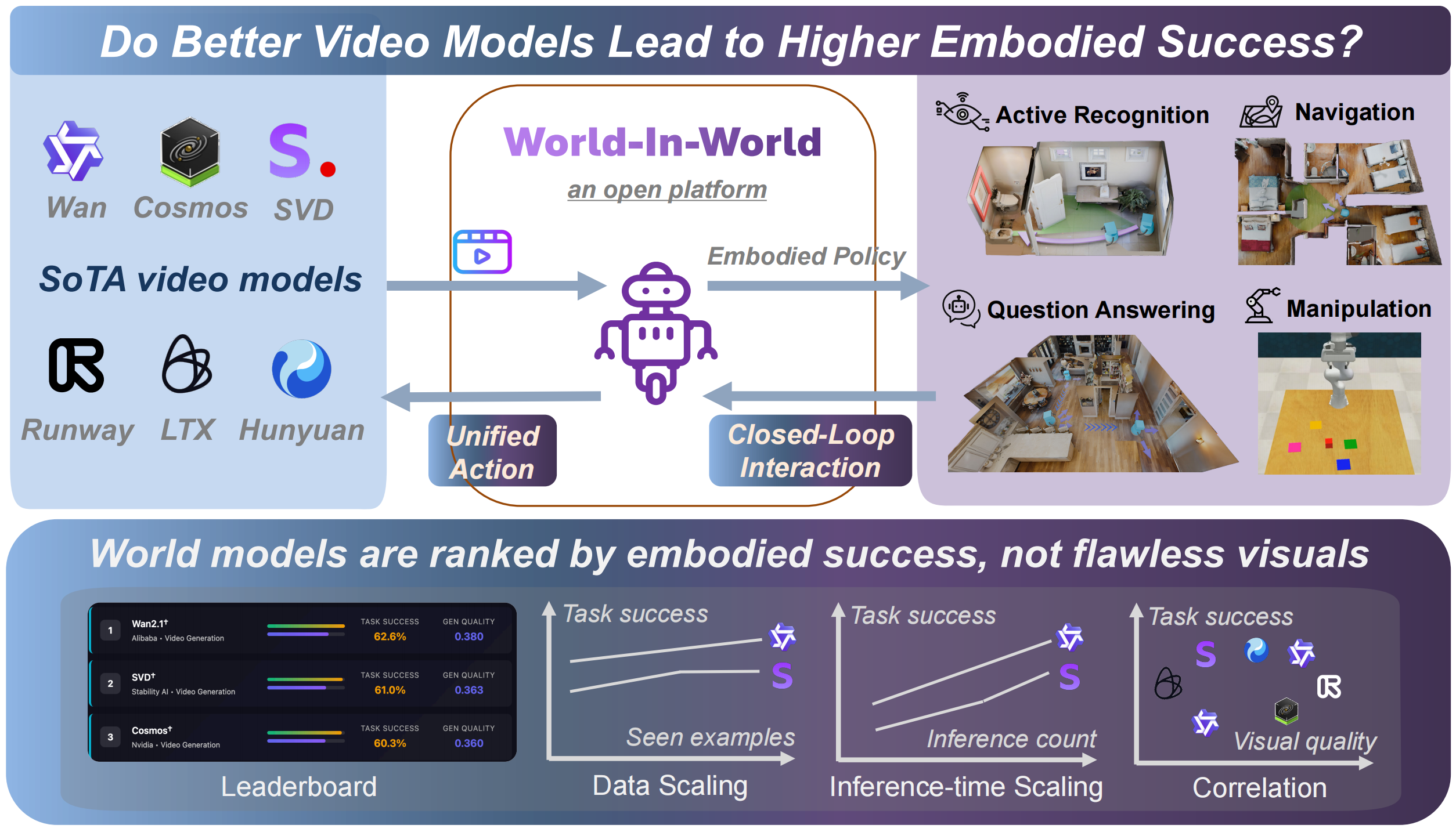
In this work, we propose ![]() , which wraps generative World models In a closed-loop World interface to measure their practical utility for embodied agents.
We test whether generated worlds actually enhance embodied reasoning and task performance—for example, helping an agent perceive the environment, plan and execute actions, and replan based on new observations within such a closed loop. Establishing this evaluation framework is essential for tracking genuine progress across the rapidly expanding landscape of visual world models and embodied AI.
, which wraps generative World models In a closed-loop World interface to measure their practical utility for embodied agents.
We test whether generated worlds actually enhance embodied reasoning and task performance—for example, helping an agent perceive the environment, plan and execute actions, and replan based on new observations within such a closed loop. Establishing this evaluation framework is essential for tracking genuine progress across the rapidly expanding landscape of visual world models and embodied AI.
Evaluation Pipeline
Closed-loop online planning in ![]() :
:
1) At time step t, the agent receives the world state, represented by observation ot.
2) Then it invokes a proposal policy πproposal (❶) to produce a total of M candidate action plans.
3) The unified action API (❷) transforms each plan into the control inputs required by the world model.
4) The world model (❸) then predicts the corresponding future states as observations Ôt.
5) The revision policy πrevision (❹) evaluates all rollouts and commits to the best, yielding decision D*t.
6) This decision is applied in the environment, closing the interaction loop.
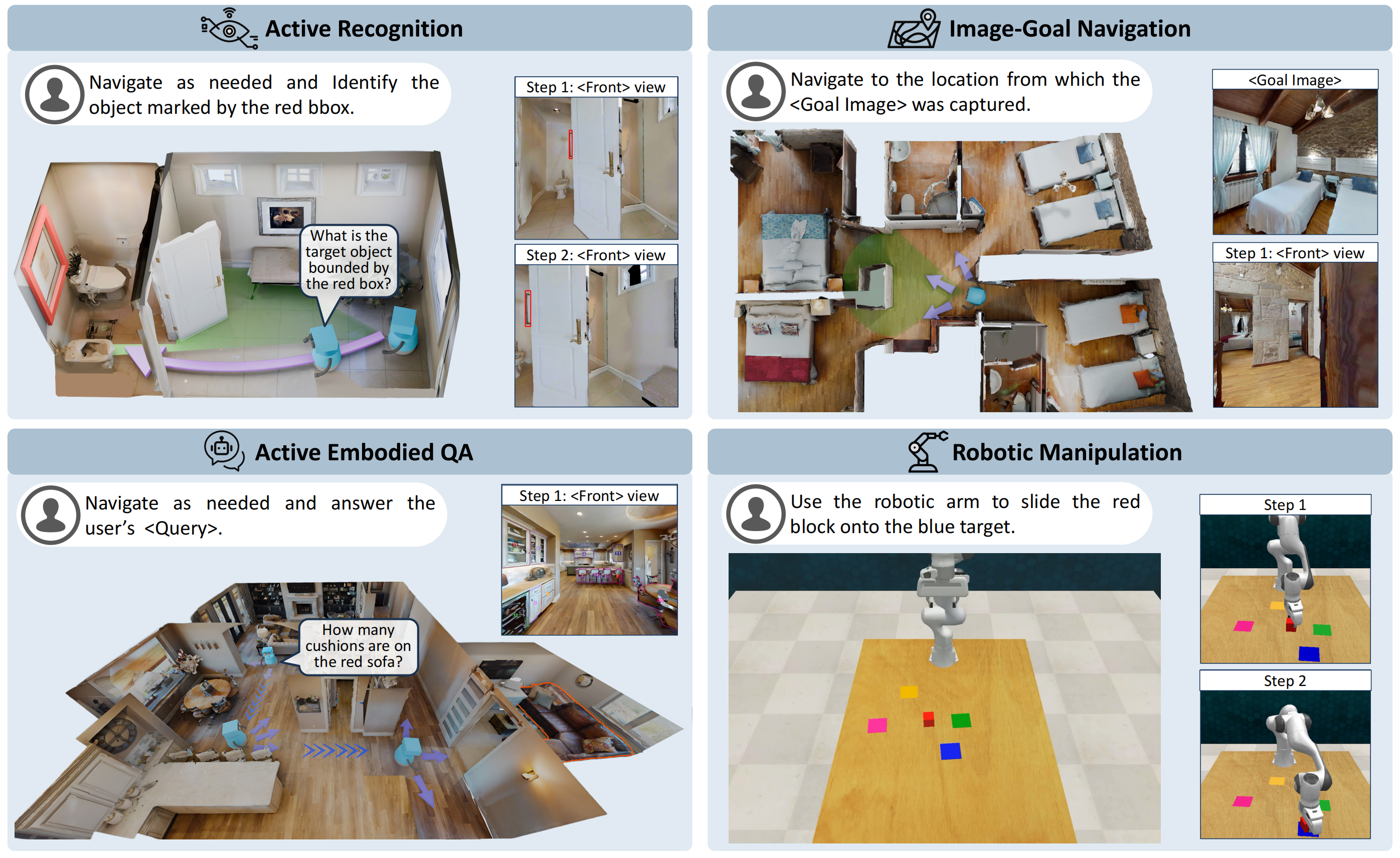
Task Examples
We provide four benchmark tasks that are carefully designed to evaluate the utility of visual world models in a closed-loop setting.
Results and Analysis
Showcase qualitative and quantitative results and analysis.
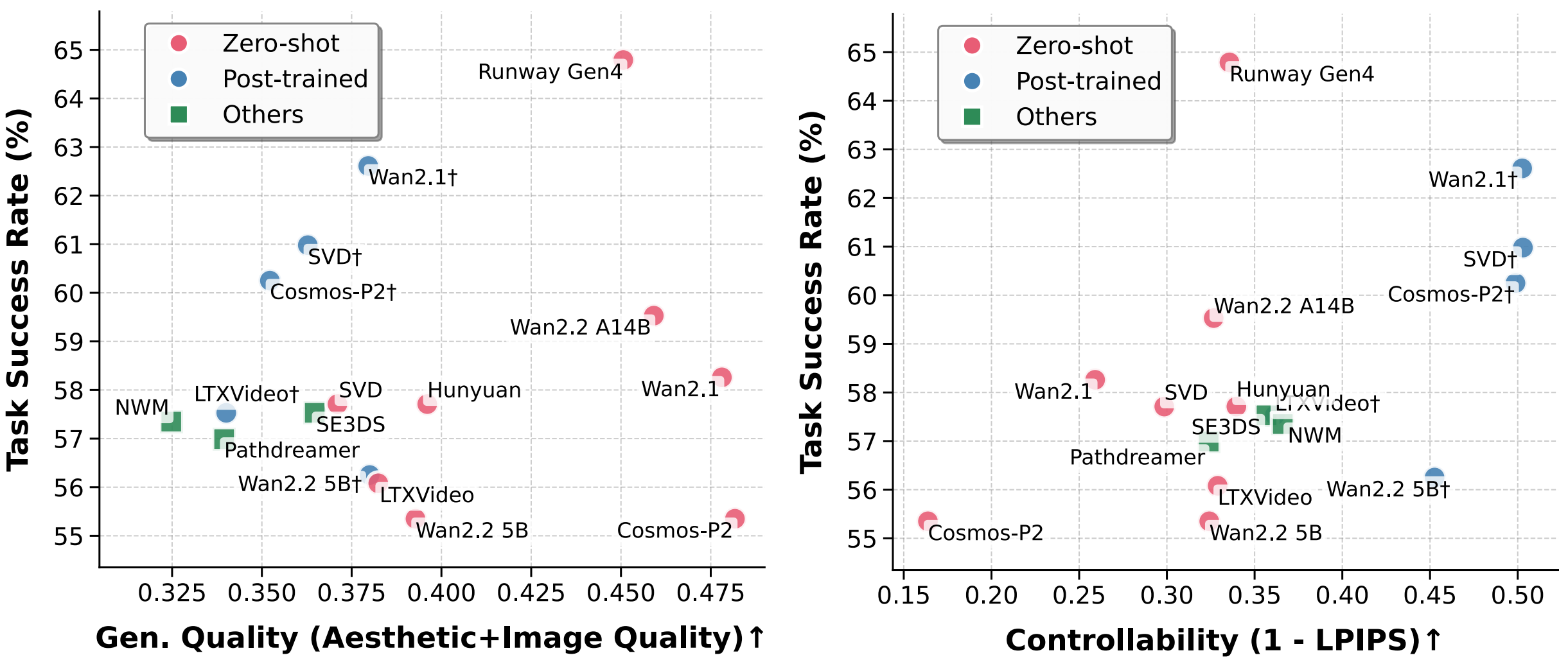
Controllability matters more than visuals for task success.
Recent video generators (e.g., Wan2.1) produce appealing clips but offer limited low-level control from text prompts, so they help embodied tasks only modestly without adaptation.
After action-conditioned post-training, action-motion alignment improves and success rates rise.
Left: Embodied task success rate vs. visual quality. † = post-trained with extra data.
Right: higher controllability correlates with higher SR. Precise control, not just visual quality, enables effective decision-making.
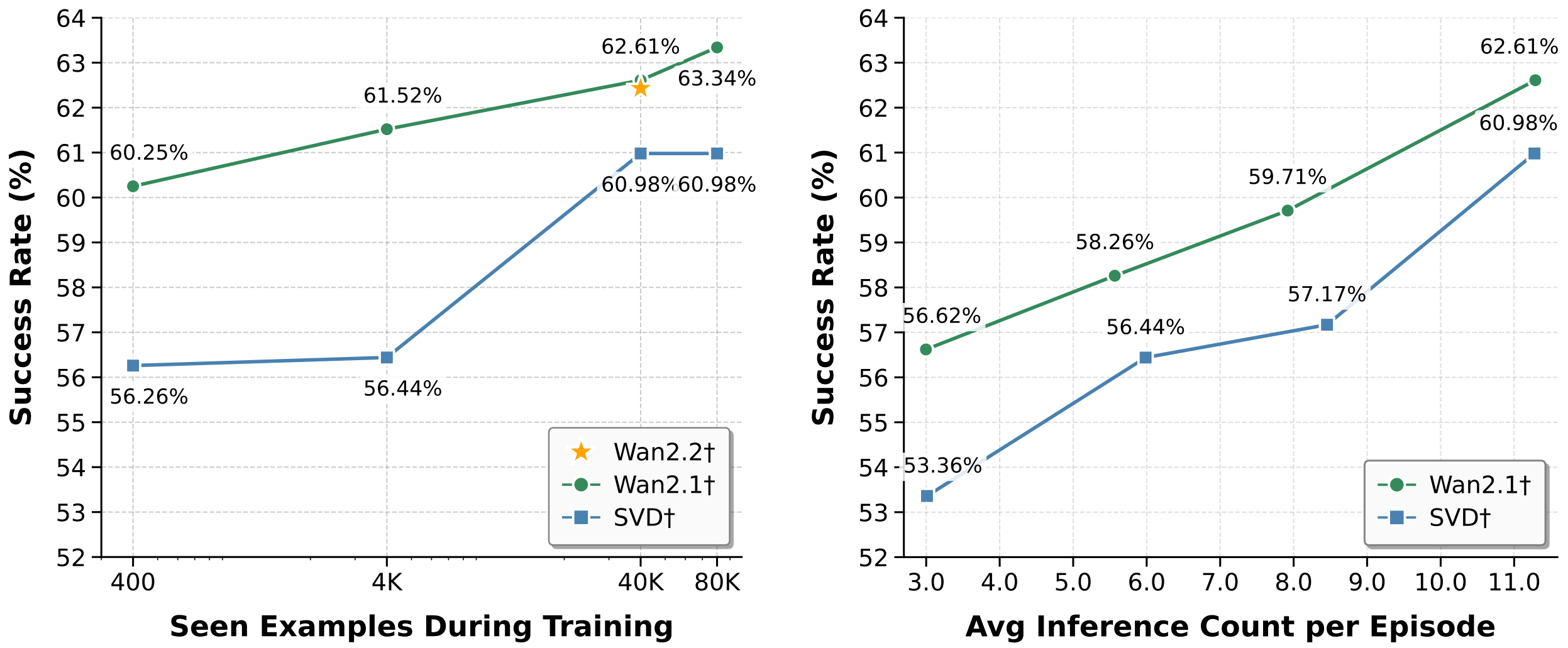
Scaling improves performance: data and inference time. Post-training data scaling: training Wan2.2†, Wan2.1† and SVD† for one epoch on 400 → 80K instances consistently boosts AR performance (e.g., Wan2.1† 60.25% → 63.34%, SVD† 56.80% → 60.98%). Wan2.2† (A14B) reaches nearly Wan2.1† after ~40K, suggesting action-conditioned post-training is more impactful than upgrading the pretrained generator. Larger models benefit more and saturate less than smaller ones. Inference-time scaling: increasing world-model inferences per episode improves AR success (e.g., SVD† 53.36% → 60.98% when raising average rollouts from 3 to 11). More simulated futures let the planner choose better actions. † denotes action-conditioned post-training.
Contact
For questions or to submit your own results, reach out at jhanzhang01@gmail.com.
BibTeX
@article{zhang2025worldinworld,
title = {World-in-World: World Models in a Closed-Loop World},
shorttitle = {World-in-World},
author = {Zhang, Jiahan and Jiang, Muqing and Dai, Nanru and Lu, Taiming and Uzunoglu, Arda and Zhang, Shunchi and Wei, Yana and Wang, Jiahao and Patel, Vishal M. and Liang, Paul Pu and Khashabi, Daniel and Peng, Cheng and Chellappa, Rama and Shu, Tianmin and Yuille, Alan and Du, Yilun and Chen, Jieneng},
journal={ArXiv},
year={2025},
volume={arXiv:2510.18135},
}